Überblick
In der KI-Vorhersage ist jeweils das beste Modell für die entsprechende meteorologische Größen dargestellt. Im Hintergrund arbeiten aber zwei sogenannte Long Short Term Memory (LSTM) Modelle als datenbasierte Maschine Learning Methoden, welche sich durch die Anzahl an Eingabegrößen unterscheiden.
Das univariante Modell erhält als Eingabegröße lediglich dieselbe Größe, welche auch vorhergesagt werden soll. Bei der Vorhersage der Temperatur also nur die vergangenen Temperaturwerte.
Das multivariate Modell erhält zusätzlich als Eingabegrößen noch andere meteorologische Parameter. Bei der Vorhersage der Temperatur also z.B. neben den vergangenen Temperaturwerten auch die vergangenen Werte der Luftfeuchte, Luftdruck etc.
Mehr Eingabegrößen führen aber nicht automatisch zu besseren Vorhersagen. So sind verschiedene meteorologische Größen auch von einer unterschiedlichen Anzahl an anderen Größen abhängig. Während die Lufttemperatur beispielsweise von vielen Parametern abhängt, (z.B. Luftfeuchte, Strahlung, Wind), ist die Strahlung nur von wenigen bis keinen abhängig. Bei mehr Parametern als nötig kann das Modell in einigen Fällen schlechter performen.
Für die Vorhersage der Lufttemperatur, Luftfeuchte, Luftdruck, Windgeschwindigkeit in 10m, Windgeschwindigkeit in 50m und die Windrichtung kam daher das multivariate Modell zum Einsatz.
Und für die globale Strahlung, diffuse Strahlung, Windboen in 10m, Windboen in 50m sowie für den Niederschlag wurde das univariate Modell verwendet.
Modelle
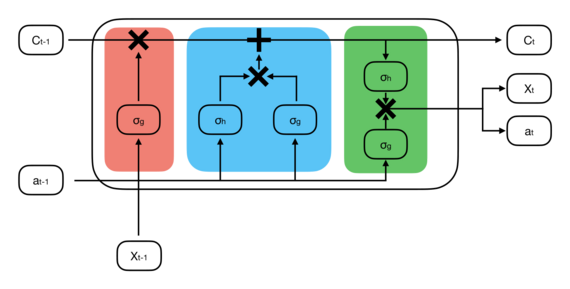
Beide Modelle basieren auf einem Machine-Learning-Ansatz. Nach einer Trainingsphase sind die Modelle in der Lage, auf Basis der Eingangsdaten selbstständig Vorhersagen zu erstellen, ohne dass vorgegebene physikalische Gleichungen notwendig sind.
Konkret wurden sogenannte Long-Short-Term-Memory-Netzwerke (LSTM) verwendet. Diese neuronalen Netzwerke, die auf Zeitreihendaten spezialisiert sind, nutzen ein "Gedächtnis", um auf frühere zeitliche Daten zurückzugreifen und so genauere Vorhersagen zu treffen. Das Gedächtnis besteht, ähnlich dem menschlichen Gehirn, aus einem Kurz- und einem Langzeitgedächtnis, wodurch es selektiv wichtige Werte und deren Zusammenhänge speichern kann. Diese Aufteilung ermöglicht ein effektiveres und robusteres Training mit längeren Zeitreihen. Analog dazu wäre das menschliche Gehirn überfordert, wenn es sich alle Sinneseindrücke jederzeit merken müsste und nicht nach wichtigen Erlebnissen filtern könnte. Intern verwenden LSTM-Netzwerke mehrere sogenannte LSTM-Zellen, die aus drei Toren (Gates) zur Informationsverarbeitung bestehen: dem Vergessenstor (Forget Gate), das irrelevante Datenverknüpfungen aus dem Kurzzeitgedächtnis entfernt, dem Eingangstor (Input Gate), das neue wichtige Informationen dem Langzeitgedächtnis hinzufügt, und dem Ausgangstor (Output Gate), welches die aktualisierten Kurz- und Langzeitgedächtnisse und somit die Vorhersage ausgibt.
Neuronale Netzwerke bieten viele Stellschrauben, um die Eingabedaten mathematisch so zu verarbeiten, dass optimale Vorhersagen erzielt werden. Dabei unterscheidet man zwischen zwei Arten von Stellschrauben: den Biases und Gewichten, die während des Trainings optimiert werden, und den sogenannten Hyperparametern. Diese umfassen übergreifende Modellparameter wie die Anzahl der LSTM-Zellen und deren Optimierungsalgorithmen.
Die Suche nach optimalen Hyperparametern ist Gegenstand aktueller Forschung und besonders herausfordernd. Für diese Modelle wurden die optimalen Hyperparameter jedoch automatisch durch einen Algorithmus für jeden vorherzusagenden Parameter einzeln bestimmt.
Trainingsdaten
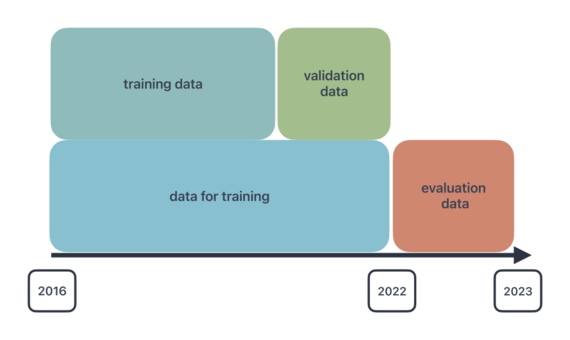
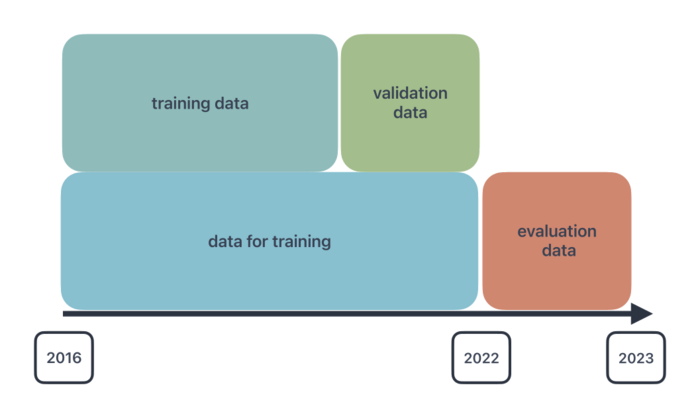
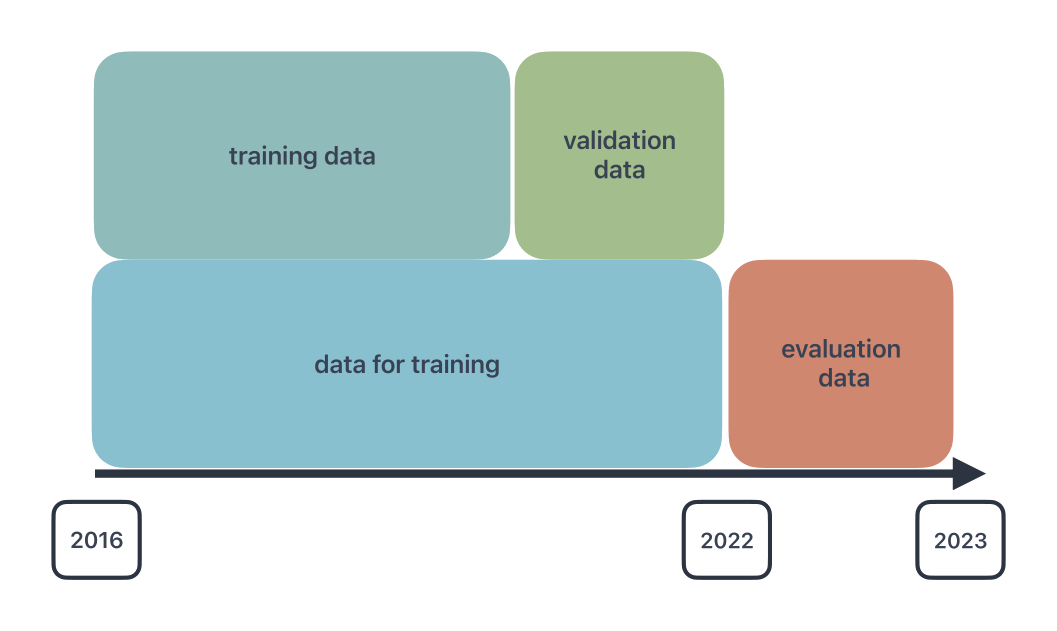
Für das Training der Modelle wurden historische meteorologische Messdaten des IMuK für den Standort Hannover-Herrenhausen verwendet. Die minütlichen Daten von 2016 bis Ende 2022 wurden auf Stundenwerte gemittelt und zusätzlich auf den Bereich zwischen null und eins normiert.
| Parameter | Einheit | Messhöhe [m] |
|---|---|---|
| Lufttemperatur | ° C | 2 |
| relative Luftfeuchte | % | 2 |
| Luftdruck | hPa | 2 |
| Windgeschwindigkeit | m/s | 10/50 |
| Windboen | m/s | 10/50 |
| Windrichtung | ° | 10 |
| Niederschlag | mm | 2 |
| Globale Strahlung | W/m² | 10 |
| Diffuse Strahlung | W/m² | 10 |
Die Daten wurden wie folgt aufgeteilt: Die Daten von 2016 bis Ende 2021 wurden für das Training genutzt (data for training), während die Daten von Anfang bis Ende 2022 zur Evaluierung dienten (evaluation data). Die Daten für das Training wurden weiter in 70% Trainings- und 30% Validierungsdaten (training data & validation data) unterteilt. Die Validierungsdaten werden im Training verwendet, um das neuronale Netzwerk daran zu hindern, die Trainingsdaten „auswendig“ zu lernen, und um die Generalisierungseigenschaften des Modells zu verbessern.
Zur aktuellen KI-Vorhersage geht es hier.





